Sprut.IO file manager
Why we do it
Here at BeGet we have a long and successful history
of working with virtual web hosting
and implementing various open-source solutions and now it's time to share our invention
with the world: Sprut.IO file manager, which we developed for our clients and which is
used in our control panel. Please feel invited to join its development. In this article
we will tell you how it was developed, why we weren't pleased with existent file
managers, which kludges technologies we used and who can profit from it.
Source code: https://github.com/LTD-Beget/sprutio

In 2010 we were using NetFTP, which handled such tasks as opening/loading/editing quite bearably.
However from time to time our users wanted to learn how to move websites between web hostings or between our accounts, but the website was too large and the internet was not the best. In the end we either had to do it ourselves (whish was obviously faster) or to explain what SSH, MC, SCP and other scary things are.
That's when we got the idea to create an orthodox WEB file manager, working on the server's site, which would be able to copy between different sources with server speed and would offer: file and directory search, a disk usage analyzer (an analogue of ncdu), simple file uploading and a lot of other great stuff. Let's say everything that would make our users' and our lives easier.
In May 2013 the file manager went into production on our web hosting. Some parts even turned out to be better than we originally planned: we created a Java applet for file uploading and access to the local file system, which allowed to select files and copy them to the web hosting or from it all at once (the destination is irrelevant, the file manager could work both with remote FTP and user's home directory, unfortunately soon browsers won't support it anymore).
After reading about a comparable manager, we decided to publish ours as an open-source product, which, as we think, proved itself to be amazing useful and highly functional. We spent another 9 months separating it from our infrastructure and whiping it into shape. Just before NYE 2016 we released Sprut.IO.
We created it for ourselves and believe to have implemented the latest, most stylish and useful and technologies. Often we used tools that had already been developed previously.
There's a certain difference between the implementation of Sprut.IO and the version we created for our web hosting, meant to interact with our panel. For ourselves we use: full-featured queues, MySQL, an additional authorization server, which is also responsible for selection of the endpoint server, where the client is, transport between our servers and the internal network and so on.
Sprut.IO contains several logical components:
1) web-face,
2) nginx+tornado, receiving all web invocations,
3) endpoint agents, that can be located both on one or on several servers.
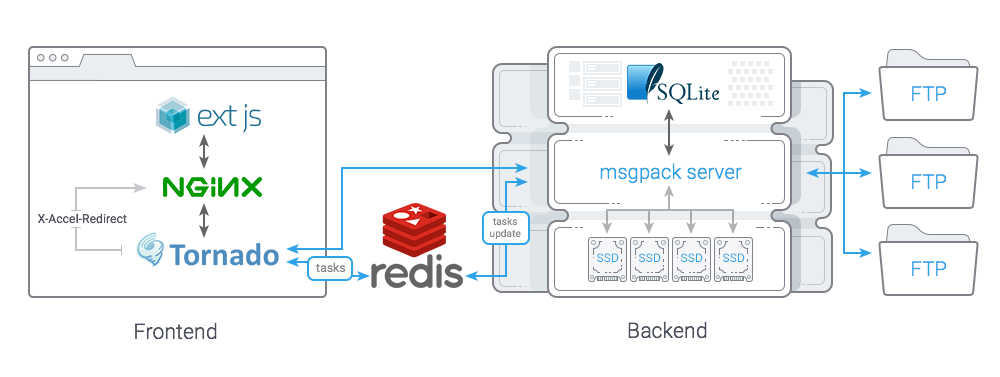
Basically you can create a multiserver file manager by adding a separate layer with authorization and server choice (as we did in our realization). All elements can be logically separated into two parts: Frontend (ExtJS, nginx, tornado) and Backend (MessagePack Server, Sqlite, Redis).
See the interaction scheme below:
There are two types of queries sent to Backend: synchronous, executed relatively fast (e.g. file listing or reading) and queries for execution of long tasks (uploading file to remote server, deleting files/directories etc.).
Synchronous queries are a usual RPC. Data serialization is implemented using msgpack, proved itself or smth to be excellent in data serialization/deserialization speed and language support. We did also consider rfoo for Python and Google's protobuf, but while the first one didn't suit because it is tied to Python (and its versions), we thought the second one was excessive since there aren't dozens and hundreds of remote procedures and there was no need intaking the API out to separate proto-files.
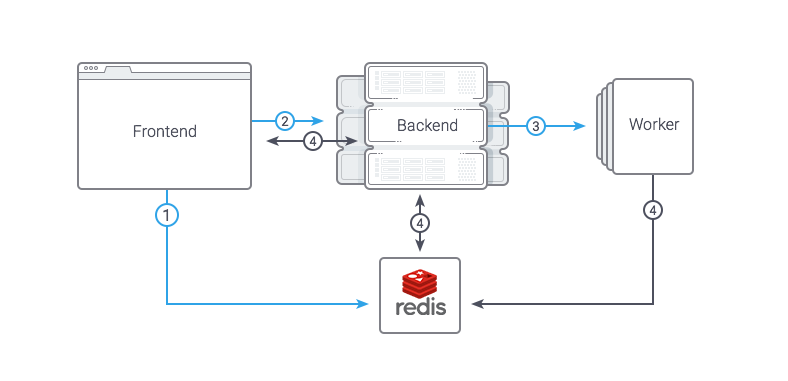
We decided to implement queries for long operations as simple as possible: There's a shared Redis between Frontend and Backend, which contains the executed task, its status and any other information. The task is started with a common synchronous RPC query. The flow looks like this:
We chose the path of least resistance and prepared Docker images instead of a manual setup. Basically the setup is performed by a couple of commands:
run.sh will check the availability of images, download them in case of absence and start 5 containers with system components. To update images, execute
Image stop and deletion can be performed via stop and rm parameters respectively. You'll find a packaging dockerfile in the project code, the packaging takes about 10-20 minutes.
There are quite a few obvious options for further improvement of this file manager.
We think most beneficial for the user would be:
If you have thoughts on what might be useful for the user, share them in the comments or in the newsletter list sprutio@groups.google.com.
Thanks for your attention! If you like, we'll be pleased to write more details about the project realization and will respond to your questions in the comments.
Project website: https://sprut.io/en
Source code: https://github.com/LTD-Beget/sprutio
English newsletter list: sprutio@groups.google.com
Source code: https://github.com/LTD-Beget/sprutio
Why invent your own file manager
In 2010 we were using NetFTP, which handled such tasks as opening/loading/editing quite bearably.
However from time to time our users wanted to learn how to move websites between web hostings or between our accounts, but the website was too large and the internet was not the best. In the end we either had to do it ourselves (whish was obviously faster) or to explain what SSH, MC, SCP and other scary things are.
That's when we got the idea to create an orthodox WEB file manager, working on the server's site, which would be able to copy between different sources with server speed and would offer: file and directory search, a disk usage analyzer (an analogue of ncdu), simple file uploading and a lot of other great stuff. Let's say everything that would make our users' and our lives easier.
In May 2013 the file manager went into production on our web hosting. Some parts even turned out to be better than we originally planned: we created a Java applet for file uploading and access to the local file system, which allowed to select files and copy them to the web hosting or from it all at once (the destination is irrelevant, the file manager could work both with remote FTP and user's home directory, unfortunately soon browsers won't support it anymore).
After reading about a comparable manager, we decided to publish ours as an open-source product, which, as we think, proved itself to be amazing useful and highly functional. We spent another 9 months separating it from our infrastructure and whiping it into shape. Just before NYE 2016 we released Sprut.IO.
How it works
We created it for ourselves and believe to have implemented the latest, most stylish and useful and technologies. Often we used tools that had already been developed previously.
There's a certain difference between the implementation of Sprut.IO and the version we created for our web hosting, meant to interact with our panel. For ourselves we use: full-featured queues, MySQL, an additional authorization server, which is also responsible for selection of the endpoint server, where the client is, transport between our servers and the internal network and so on.
Sprut.IO contains several logical components:
1) web-face,
2) nginx+tornado, receiving all web invocations,
3) endpoint agents, that can be located both on one or on several servers.
Basically you can create a multiserver file manager by adding a separate layer with authorization and server choice (as we did in our realization). All elements can be logically separated into two parts: Frontend (ExtJS, nginx, tornado) and Backend (MessagePack Server, Sqlite, Redis).
See the interaction scheme below:
Frontend
Web interface; the whole thing is quite simple, ExtJS and a looot of code. Code written in CoffeeScript. In the first versions we used LocalStorage for caching, but in the end we decided against it since there were more bugs than benefit. Nginx is used to serve static content, JS code and files via X-Accel-Redirect (read more below). The rest is just proxied to Tornado, which in turn is a kind of router, redirecting queries to the correct Backend. Tornado can be perfectly scaled and we hope to have killed off all blockings we had created ourselves.Backend
Backend consists of several demons that, as usual, can receive queries from Frontend. The demons are located on each endpoint server and work with the local file system, upload files via FTP, perform authentication and authorization, work with SQLite (editor settings, access to user's FTP servers).There are two types of queries sent to Backend: synchronous, executed relatively fast (e.g. file listing or reading) and queries for execution of long tasks (uploading file to remote server, deleting files/directories etc.).
Synchronous queries are a usual RPC. Data serialization is implemented using msgpack, proved itself or smth to be excellent in data serialization/deserialization speed and language support. We did also consider rfoo for Python and Google's protobuf, but while the first one didn't suit because it is tied to Python (and its versions), we thought the second one was excessive since there aren't dozens and hundreds of remote procedures and there was no need intaking the API out to separate proto-files.
We decided to implement queries for long operations as simple as possible: There's a shared Redis between Frontend and Backend, which contains the executed task, its status and any other information. The task is started with a common synchronous RPC query. The flow looks like this:
- Frontend puts a task with the status "wait" into Redis
- Frontend sends a synchronous query to Backend, handing over the task ID
- Backend receives the task, sets the status "running", uses fork and executes the task in a child process, sending a response right to Backend
- Frontend views the task's status or controls changes of any data (such as number of copied files, which is being updated by Backend from time to time).
Interesting cases, worth mentioning
Uploading files from Frontend
Task:
Upload files to endpoint server while Frontend does not have access to the endpoint server's file system.
Solution:
ДMsgpack server didn't suit for file transfer, mainly because the package could not be transferred by bytes, but only at once (first it needs to be completely loaded into memory and only then be serialized and transferred, in case of a large you'll run out of memory), so in the end we decided to use a separate daemon for that. The operation process looks as following:
We receive a file from Nginx, write it into our daemon socket with a title, containing the temporary file location. After completion of the file transfer we send a query to RPC to transfer the file to its final location (to the user). To work with the socket we use the pysendfile package, the server is selfwritten, based on the standard Python library asyncore.
Parallel charset-aware text search in files
Task:
Implement text search in files with the option of using "shell-style wildcards" in the name, that is for instance 'pupkun@*com' '$* = 42;' etc.
Problems:
The user searches for "Контакт", but the search result shows no files with this text while actually they do exist. It's just that there can be many different charsets on the web hosting, even within one project, so that the search needs to consider this as well.
A couple of times we observed a situation when by mistake users were able to put in any lines and perform some search operations in a big amount of folders, which led to a load increment on servers.
Solution:
We organized multitasking quite commonly by using the multiprocessing module and two queues (list of all files, list of found files with included listings). One worker builds the file list, the others review it at the same time and perform the search itself.
The searched line can be imagined as a regular expression, using the fnmatch package. Link to final implementation.
The final implementation contains the additional option of setting execution time in seconds (timeout), set to 1 hour by default. The execution priority is lowered in the worker processes to drop the disk and processor load.
Unpacking and creating file archives
Task:
Give users a possibility to create archives (zip, tar.gz, bz2, tar available) and to unpack them (gz, tar.gz, tar, rar, zip, 7z).
Problems:
We faced a multitude of problems with "real" archives, such as file names in cp866 charset (DOS) and backslashes in filenames (windows). Some libraries (standard ZipFile python3, python-libarchive) didn't work with cyrillic names within the archive. Some library implementations, such as SevenZip or RarFile can't unpack empty folders and files (archives with CMS have a lot of them). Also users always like to see the execution process, which is impossible if the library doesn't allow (for instance if it just uses the extractall() method).
Solution:
The libraries ZipFile and libarchive-python had to be edited and connected as separate packages to the project. We had to create a library fork for libarchive-python and adjust it to Python 3.
Creation of zero size files and folders (bug found in SevenZip and RarFile libraries) had to be organized in a separate loop in the very beginning after file names in the archive. We contacted the developers concerning all bugs. As soon as we'll find some time, we'll send them a pull request, seems like they're not planning on fixing it themselves.
Gzip editing of compressed files (for SQL dumps etc.) has been created separately, which was possible without kludges with a standard library.
The operation progress can be controlled via a watcher with the system call IN_CREATE, using the pyinotify library. It sure doesn't work very accurately (the watcher doesn't always react, especially if there's a high number of files, that's why there's the magical coefficient 1.5), but it does show something similar. Not a bad solution, keeping in mind that there's no way to tracing that without rewriting all archive libraries. Прогресс операции отслеживается с помощью вотчера на системный вызов IN_CREATE, используя библиотеку
Code unpacking and creating archives.
Raising security requirements
Task:
To keep the user from getting access to the endpoint server.
Problems:
Everyone knows that a web hosting server can host many hundreds of websites and users at the same time. First versions of out product allowed workers to execute some operations with root-priveleges, which theoretically (maybe) could have allowed to get access to someone else's files and read something you shouldn't or break it.
Sadly we can't give concrete examples. There were some bugs, but they didn't really have any influence on the server and also rather were our errors than a security hole. Anyhow, the web hosting infrastructure provides tools for load decreasing and monitoring, in the open-source version however we decided to seriously improve security.
Solution:
All operations had been extracted to so-called workers (createFile, extractArchive, findText) etc. Before getting started each worker performs a PAM authentication and a setuid user.
Whereby all workers work each separately in its own process and vary in its wrap (waiting or not waiting for response). That's why, even if the algorithm of one operation might be fragile, there's an isolation on the level of system permissions.
Neither does the application architecture allow to receive direct access to the file system, e.g. via the web server. This solution allows it to control the load quite effectively and monitor user activity on the server by any external means.
Setup
We chose the path of least resistance and prepared Docker images instead of a manual setup. Basically the setup is performed by a couple of commands:
user@host:~$ wget https://raw.githubusercontent.com/LTD-Beget/sprutio/master/run.sh user@host:~$ chmod +x run.sh user@host:~$ ./run.sh
run.sh will check the availability of images, download them in case of absence and start 5 containers with system components. To update images, execute
user@host:~$ ./run.sh pull
Image stop and deletion can be performed via stop and rm parameters respectively. You'll find a packaging dockerfile in the project code, the packaging takes about 10-20 minutes.
Help us improve Sprut.IO
There are quite a few obvious options for further improvement of this file manager.
We think most beneficial for the user would be:
- Add a terminal
- Add option for work with Git
- Add file sharing option
- Add theme changing, configuration and creation of various themes
- Create a universal interface for work with modules
If you have thoughts on what might be useful for the user, share them in the comments or in the newsletter list sprutio@groups.google.com.
Thanks for your attention! If you like, we'll be pleased to write more details about the project realization and will respond to your questions in the comments.
Project website: https://sprut.io/en
Source code: https://github.com/LTD-Beget/sprutio
English newsletter list: sprutio@groups.google.com